I hope that got your attention. However, this post is about defining terms well so that your business architecture and how your business operates does not get bloated simply because people conflate different concepts.
I’m using the concept of ‘hate’ crime because I happen to be discussing the topic with someone on Twitter and it illustrates an important point about modelling business concepts.
Having seen a tweet decrying the fact that Ireland does not have any legislation against hate crime, I tweeted: ‘I don’t understand ‘hate crime’ laws. If someone [intentionally] stabs me, should it matter whether they hated me or not? Feel free to educate me.’
Moreover, if someone stabbed me, I would not want them to receive a different punishment based on whether their motivation was my skin colour, or the fact that I’m bald, or robbery, or anything else. I would certainly want the motivation to be recorded, however. By the way, I was assaulted once, by someone who made it clear with their words that the motivation was my skin-colour.
In response, I was sent the following argument:
Yes, it does matter. Obviously, any crime impacts on a victim. Hate crime has further impact as hate crime victims imply assert that their experience was an unlucky occurrence (wrong place, wrong time), they are forced to accept that their identity was targeted and they remain at risk of repeat victimisation. Fear of being targeted impacts on the way people live their lives, with victims changing the way they live, limiting their use of public space, etc. Hate crime’s ripple effect is also significant. As well as impacting on the victim, it sends a message to that community.
It would seem, therefore, that the intent is to acknowledge the motivation for the crime and to use that knowledge to educate victims and society at large and to enable us to tackle the root causes of such motivations and therefore the crimes themselves.
However, to achieve that, you don’t need separate legislation against attempted murder and attempted murder because the perpetrator hates, say, people with brown skin. You simply need to be able to record the motivation for the crime against the crime itself. One crime on the statute books, many possible motivations for that crime. That would be sufficient to provide the data needed for education and prevention programmes.
Having separate legislation for each motivation has several disadvantages without improving data for education and prevention:
- Increased statutes and the corresponding time and effort involved in debating and adding such statutes
- Operational overhead in having to add a new statute each time a new motivation is uncovered (as opposed to simply adding a new motivation to an existing statute)
- Risk of allowing different levels of sanction against the same crime for different motivations
For those who want particular hate crimes, or hate crimes in general, to be addressed, it would be quicker, more effective and cheaper to campaign to have a new motivation added to crime reporting than to have a new statute added.
Actions and the reasons for those actions are related but distinct. Modelling them as the same thing makes for inefficient and ineffective operations, whether in terms of criminal statutes or business operations.
I have another reason for being against “hate” crime legislation. Once you allow the government to criminalise hate itself (as opposed to actions, probably already illegal, motivated by hate), you allow the government to define what constitutes “hate”. Do you really want to open a door that could allow the government to define criticism of a minister as “hate”?
Is there a flaw in my reasoning? Let me know. If you can sell me your argument, I’ll spin on a sixpence.
Kind regards.
Declan Chellar
In this blog post I aim to provide an appraisal of the Pega Developer Network articles “What is the SmartBPM Methodology?” and “Using Pega BPM with PRPC“, based on my experiences working on Pega projects in the field.
I am a Certified Pega Business Architect (7.2) and Pega Methodology Black Belt, and here I provide an alternative to SmartBPM (now known as PegaBPM), which I hope addresses what I perceive to be the shortcomings of the methodology. This post addresses the SmartBPM methodology only and not the Pega Scrum methodology. Moreover, it does not address techniques specific to any discipline (e.g., use case modelling).
Note that Pega clearly states that the SmartBPM methodology “is not a concrete prescriptive process”, that it is adaptable and that the phase information is an outline only. Therefore some of my suggestions are nothing more than an adaption of the methodology and others merely add detail to what is currently in outline form. However, other suggestions are the result of the problems I see with the original PDN article or with the methodology itself. You can download the full appraisal in PDF form from the link below, but here are what I consider to be the critical flaws in SmartBPM.
Continue reading Review of the PegaBPM Methodology
If you are a Pega Business Architect, you will be familiar with Pega’s feature that lets you connect Business Objectives, Requirements and Specifications.
This feature is excellent for traceability but it may surprise you to know that I don’t use it exactly the way Pega tells you to.
Business Objectives
‘Business objectives illustrate how the Pega application delivers value to the business’1
It’s important that everyone on a Pega development understands what value they are trying to deliver to their customer because software delivery is not an end in itself, it is merely a means to the true end, which is realisation of the desired business benefit (which should be stated in the business case and encapsulated in the Business Objectives). Yet you’d be surprised at how few projects (in my experience) actually document Business Objectives in Pega. I’ve even worked on projects where no one on the team could tell me what they were or where they were documented. Not only do I document them, I also like to print them out and stick them on the wall so everyone keeps sight of them. Pega encourages you to keep Business Objectives SMART, which is absolutely correct, and provides you with the means to capture them:
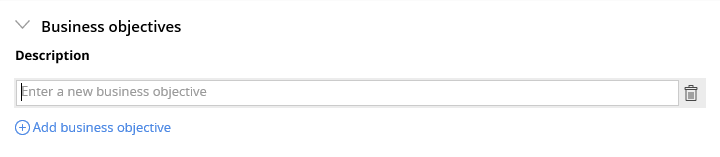
However, I have some reservations. Firstly, any Pega project I’ve been on has had a wider scope than the Pega solution, usually involving other technologies as well as non-technological business changes, so there will be Business Objectives which are important to the success of the change initiative but which are not relevant to the Pega solution. Thus it makes no sense to make Pega the golden repository of Business Objectives, rather, I would document the Business Objectives in the business architecture repository and put a reference in Pega to the ones relevant to the Pega solution.
Moreover, while you can write a SMART one-liner, I like to put a lot more meat on strategic business goals. Click here to see what I mean.
Requirements
‘One or more requirements define the criteria for the successful implementation of a specification.’2
Pega allows you to capture Requirements via the following form:
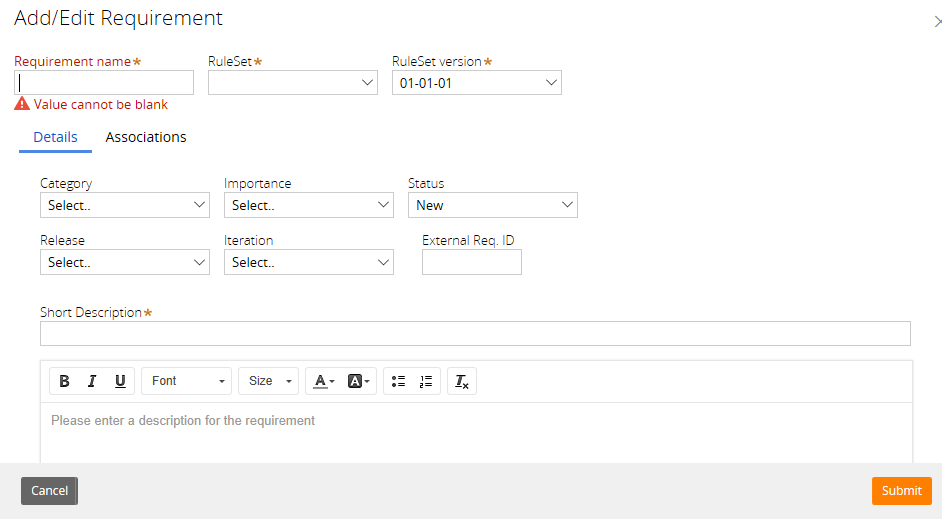
This form has hardly changed at all since Pega first introduced DCO in 2008. That’s not a bad thing in itself because many organisations still develop software the way they did in 2008 and the tool caters for that. In any case, if you don’t think it’s broken, why fix it?
My preference these days is to work with User Stories rather than Use Cases. The Pega Specification (see below) allows you to document either User Stories or Use Cases. The statement above, talks about Requirements as if they were User Story Acceptance Criteria, which they are, in my opinion, if you are taking a User Story approach.
The main problem I have always had with the Requirement form in Pega is that there is no way to indicate which Business Objective the Requirement is supposed to support. If you are following Pega’s methodology, you first document Business Objectives and then an initial set of Requirements. However, since you cannot link the two directly, the opportunity for scope creep is there. I suspect this lack of linking is also part of the reason people often ignore Business Objectives.
Specifications
‘Specifications use business language to describe the steps needed to meet a requirement.’3
That’s what Pega says Specifications are for but it’s not what I recommend. Pega allows you to document Specifications as either Use Cases or User Stories and since my preference is for the latter, let’s stick with that. I prefer Mike Cohn’s definition of a User Story:
‘User stories are short, simple descriptions of a feature told from the perspective of the person who desires the new capability, usually a user or customer of the system.’ – Mike Cohn4
I also like the description of User Stories as ‘placeholders for a conversation’; that being the case, a Specification in Pega is effectively a useful placeholder for anything you care to document about that conversation (business background, diagrams, acceptance criteria, technical solution designs, risks, assumptions, links to further useful information, etc.). Remember, Agile principles promote conversation over documentation, not instead of documentation.
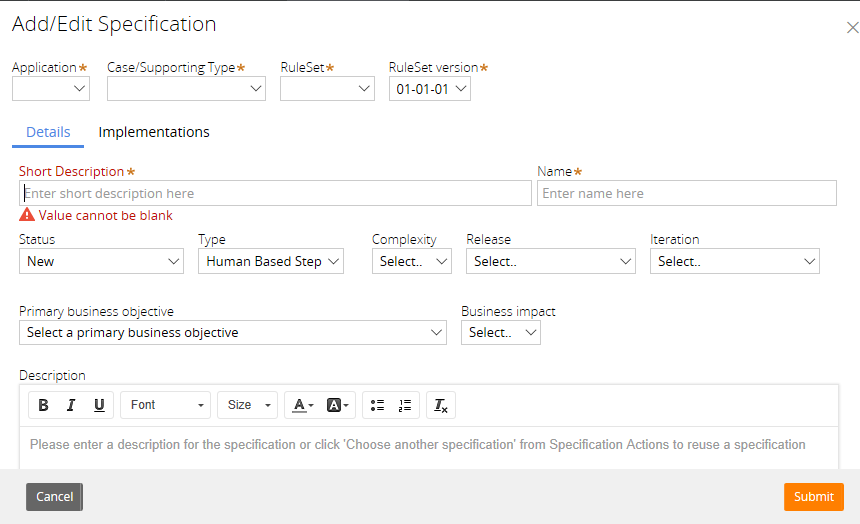
Notice that it is a Pega Specification that you link back to a Business Objective (unfortunately, only one), so although the sequence of creation is supposed to be: Business Objective –> Requirement –> Specification, the mechanism of traceability is, in fact: Business Objective –> Specification <– Requirement.
Notice that you can document both Acceptance Criteria and Requirements against a Pega Specification of type User Story:
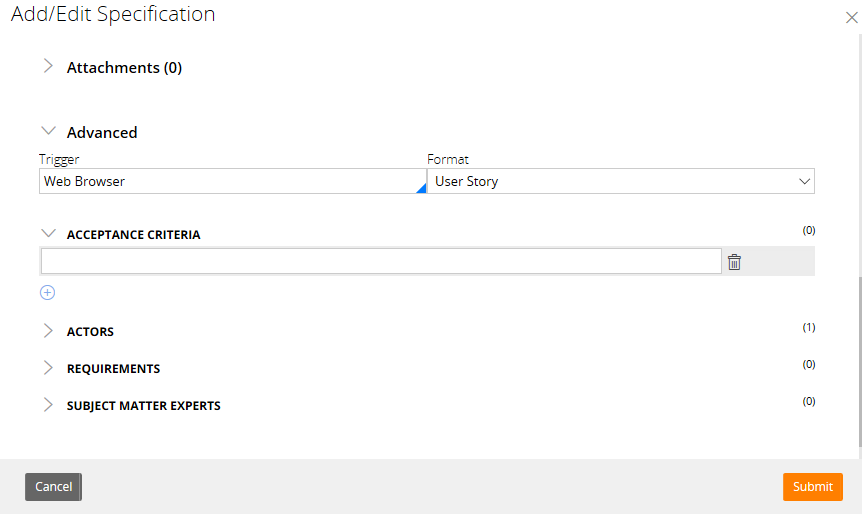
As I said, I consider the Acceptance Criteria of a User Story to be Requirements and judging by Pega’s definition of the purpose of Requirements (‘requirements define the criteria for the successful implementation of a specification’), perhaps they would agree. Therefore, I would not add both Acceptance Criteria and Requirements to my Pega application. Instead I would:
- Document Business Objectives
- Add User Stories from the customer’s Product Back Log in the form of Specifications
- Document Requirements or Acceptance Criteria against those Specifications
Note that if you document Requirements as Acceptance Criteria, you only get to add a single line of text. However, if you document Acceptance Criteria as Requirements, you get the richness of the Requirements form (see above).
Although my approach is not how Pega’s training says to do it, it does give you traceability from the outset: Business Objective –> Specification –> Requirement / Acceptance Criterion
Full credit to Pega for not enforcing their way of doing it. That’s the right approach to methodology: adapt it to your needs.
What have your experiences been?
Kind regards.
Declan Chellar
For any kind of enterprise-wide change initiative, if you derive your backlog of Business Stories only from interviews with users, you may to end up with a patchwork of individual needs that don’t necessarily hang together, some of which will conflict with each other and which won’t give you the enterprise picture.
If you don’t already know why I say “Business Stories” instead of “User Stories”, click here for some pre-reading.
Some time ago I worked on a programme that was already in sprint 8 of its software development by the time I joined. Two large walls were plastered with index cards representing Epics and User Stories. Considerable time was spent daily on re-arranging those cards, involving at least two senior business analysts and the Product Owner. After a week, I asked what they were doing and I was told that they were trying to organise the cards so that they represented the relevant business processes. My response was something along the lines of: ‘Surely the business architecture that drove out these stories already shows the relevant business processes.’
I admit, I knew there was no business architecture and that I would get blank looks but I wanted to make an important point, which is that you should derive your initial Product Backlog from your business architecture, not try to reverse-engineer your business architecture from a bunch of User Stories.
That conversation led to another one with the Product Owner and not long afterwards I was asked to work in parallel with the software development project to help the business define its technology-agnostic architecture and use that to verify whether the Product Backlog contained the right stories.
It turned out that many of the stories were wrong, or duplicated other stories, or conflicted with other stories and that no amount of re-arranging the index cards was going to tell the over-arching story: “What is the very nature of this business for which we are spending millions on software development?”
One of the key things missing was a common understanding of the strategic objectives of the programme. I eventually managed to trace down a list of them in a slide deck attached to an email (that’s right, not in a repository where anyone could find them easily). They were poorly worded, with no indication of who owned each goal, what time frame was needed or what the business value was. In fact, a set of well-structured business goals should be the starting point of your Product Backlog.
Also missing was an understanding of the business taxonomy. The organisation involved had thousands of employees, all of whom originally came from other parts of the enterprise. To use fruit as an analogy, some said ‘mandarin’, while others said ‘clementine’, when they both meant ‘orange’, so there was some duplication of user stories that was not obvious either to the Product owner or the senior business analysts. In other scenarios, multiple groups said ‘apple’, when one really meant specifically ‘granny smith’, others meant ‘royal gala’ and yet others ‘bramley’, so in some cases there was only one user story when several were needed and, again, that was not obvious either to the Product owner or the senior business analysts. In some areas of the business it was even worse: they didn’t know whether the concepts they were talking about were apples or oranges or even whether they were fruit at all.
By the way, this lack of consistency when it comes to naming and defining important concepts is common in organisations where ‘dialects’ develop over time as the enterprise grows, especially if that growth is due to acquisition of other companies. A well-formed enterprise-wide business taxonomy is an essential lingua franca.
A robust (by which I mean mature, tested but open to change) business taxonomy will suggest many candidate Business Stories. All you have to do is look at each thing defined in the taxonomy and ask whether key roles need to be able to CRUD it and you end up with candidate Business Stories along the lines of ‘So that [business value], as a [role] I need to be able to [create/read/update/delete] a [business concept]’.
Another problem on that programme of work was a total absence of business process models, which is why the senior BAs were trying to reverse-engineer processes from the Product Backlog. In fact, robust process models suggest candidate epics and stories. You could argue that a whole process can be represented by an epic. You could also argue that a particular path through a process can be represented by an epic. Either way, once you get down to atomic activities in your process model, you have candidate stories. The role represented by the relevant swimlane suggests the actor in the story (caveat: but not always), while the label on the activity itself suggests the narrative. The only thing missing from the diagram, although it should still be accessible as part of the meta-information of the model, is the business value of performing that activity.
These are the main examples of how your business architecture can be used to drive out a candidate backlog of epics and stories. Sometimes further analysis will reveal stories that aren’t covered by anything in the business architecture, in which case you update the models of the architecture to reflect the new understanding.
How do you derive your initial enterprise-wide Product Backlog?
Kind regards.
Declan Chellar
Pega 7’s case life cycle modelling tools enable you to quickly model and demonstrate a high-level process design within Pega in front of your customer.
The tools I’m talking about are the life cycle view of a case type and the flow view of a process within a case type. While these are useful tools for the high-level technical solution design and, importantly, getting your customer on-board with that design, I do not see them, strictly speaking, as business analysis tools.
Here, in Part 1, I explain some terms for BAs who may be new to Pega.
Case Type
You may think this is analogous to a business entity, especially when you see examples of Case Type names as noun structures, e.g.: Expense Claim, Vacation Request, Loan Application, Customer Order, etc.. The reason we use noun structures in data models and business glossaries is to emphasise the static nature of the model and to allow us to fully understand what something is separately from how we process it. However, the Pega glossary definition of a Case Type uses the language of process: ‘A case type represents work in your application that follows a life cycle, or path, to completion‘ (the bold type is my emphasis).
If you’ve taken the Pega BA training course, you may remember the training material says: ‘A case type is a type of artifact in Pega used to define the tasks and decisions needed to resolve a case’ and ‘Case types model how and when work gets done‘ (the bold type is my emphasis). Pega also says a Case ‘delivers a meaningful business outcome to a customer, partner, or internal stakeholder’.
If you’re a business analyst new to Pega, these statements might strike you as more akin to definitions of a business process (hover here to see my definition), whereas you might understandably think of a ‘Case’ as a business entity. Indeed, the Case Designer in Pega is essentially a tool for designing the high-level implementation of a process. So when you are discussing Case Types with your team, be aware that it has a data model aspect (the What) and a life cycle aspect (the How). That Pega wraps the what and the how together in the Case Type has an impact on how you choose to model the business, as I shall explain in Part 3.
Stage
In Pega terms, a Stage ‘is the first level of organizing work in your case type’. You may by now have studied my slide deck on defining process scope, in which case you will know that my first iteration of a process model only addresses the Key Stages of the process. This is the highest level view of how a process breaks down into activities. This is similar to what Pega calls a ‘Stage’. One main difference is in the naming convention. Pega uses a noun phrase, whereas I use the BPMN convention of modelling key stages as sub-processes, thus I name them with verb phrases.
Another important aspect of a Stage in Pega is that each stage typically represents tasks performed by a different role. For example, an expense claim can go through submission, review and payment stages, with the Case assigned to a different role at each stage. At the very least, a Stage is one or more Processes (see below) that must be completed before then next stage can begin, even if only one role is involved.
This concept of a Stage in Pega is inseparable from the concept of a Case. This also has an impact on how you choose to model the business.
Process
In Pega terms, ‘processes are organized within [my emphasis] stages and define one or more paths the case must follow’. In other words, in Pega, each possible path through a Stage is a separate process. Here is an important difference in language between a business analyst trained in process modelling using BPMN and a Pega business analyst.
In BPMN a Stage is a sub-set of a Process. In Pega 7, a Process is a sub-set of a Stage.
Alternate
In Pega 7. the terms ‘alternate’ and ‘exception’ are synonymous. ‘Use alternate stages to organize the process steps used to manage exceptions from the primary path’. To my mind the word ‘alternate’ refers to a different way to achieve your original objective; it’s a deviation from the normal path but you still end up where you wanted to go. An ‘exception’, on the other hand, deviates from the normal path but does not lead you to your desired outcome. Be aware that many software developers only use ‘exception’ to mean technical exceptions (e.g., what to do when a particular system doesn’t respond to a request), rather than business exceptions.
Participant
In Pega 7, a Participant is an actor who performs activities. The term for this in BPMN is Performer. A Participant in BPMN is an entity (external to your process) or another process, that interacts with the process you are modelling.
I’m not pointing out these differences as a criticism of Pega but to make you aware of them, so that when you hear Pega Systems Architects using them, you don’t get confused.
In Part 2, I’ll compare Pega’s Case Lifecycle Model with BPMN 2.0.
Kind regards.
Declan Chellar
Related posts:
On software development projects people have to estimate the effort involved. In doing so, one of the things analysts are asked to consider is the complexity of a process, but it surprises me how often analysts confuse complexity with difficulty.
The two concepts are mutually exclusive. A process can be simple, but difficult to implement. Another process could be complex, but simple to implement. Yet another, simple and easy or complex and difficult.
Complexity is a measure of how many possible paths there are through a process. The terms of reference will be specific to each organisation, but the least complex process is one that has a single path (regardless of the number of steps along that path). The measure of complexity increases with the number of possible paths and possible outcomes. Based on whatever measurement applies within their organisation, it is the Business Analyst who evaluates the complexity of a process.
Difficulty, on the other hand, is a measure of how hard it is to implement a process. Difficulty often arises because one or more steps in a process require one system to interface with another. As such, difficulty is for the Technical Architect to measure, not the Business Analyst.
However, if you are a Pega Business Architect documenting specifications for Pega implementations, you should note that the Specification template has an attribute of ‘Complexity’ which is used to mean ‘estimated level of effort’. The Business Architect Essentials Student Guide for Pega 7.2 says on page 155:
‘Select the estimated level of effort ( high, medium, or low) to implement the specification. This helps you plan your project where you can focus on high complexity tasks earlier on in development since they will likely take more time to create.’
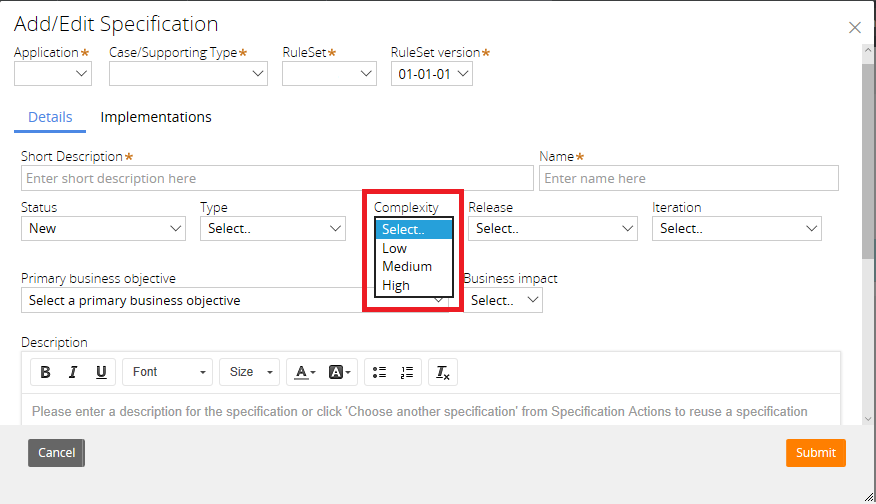
Since there isn’t a field in the Specification template for ‘level of effort’, the implication here is that ‘Complexity’ in Pega means level of effort (i.e., difficulty). Any Pega Lead Systems Architect I have discussed this with has confirmed the ‘Complexity’ field in the Pega Specification template is used to indicate technical difficulty, rather than complexity.
Kind regards.
Declan Chellar
The slide deck below is an introduction for process modelers to the Level 1 Palette of shapes for Business Process Modelling Notation 2.0.
When I was new to the BPMN palette years ago, I used it as I had used any other process flowcharting palette previously, i.e., I used the shapes as I saw fit. I did not realise that each shape has a specific semantic and that there is a specification behind the notation that is managed by the Object Management Group. Once I realised that I couldn’t just make it up as I went along, I sought out training and certification, which I achieved with Bruce Silver, BPMN Yoda and author of “BPMN Method and Style“.
If you are new to BPMN, I hope this slide deck will be useful as an introduction to how to use the shapes of the Level 1 Palette.
Note that I have updated the slide deck (it’s now version 1.3), so if you’ve seen it before, you might like to have another look.
Kind regards.
Declan Chellar
Related posts:
In my experience, very few business analysts produce models of the things a business cares about.
Of course my experience is that of one person across the whole IT industry, so my view is a thin slice through a very big cake. What’s more, my experience is limited to process-driven projects. I have no experience in, for example, Data Warehousing.
By “data model” I mean a representation of data needs. For the purposes of business architecture, such a model must be technology-agnostic and easily understood by the people who operate the business (both the BIZBOK and the BABOK use the term ‘information model’). Lately, I have started using the term “business taxonomy” but it’s important to state that this is not just a stenographed glossary of terms as dictated by the business (see ‘Things aren’t the same just because you treat them the same‘).
I started in IT in 1996 as a graduate trainee ‘Systems Engineer’ with Electronic Data Systems (EDS). The first technical skill everyone on the training programme was taught was modelling a business’s data needs using an Entity Relationship Diagram. On my first big project a few years later, we also modelled data needs in the form of a Logical Class Model (which, although technology-agnostic, did not provide an adequate taxonomy of the business). However, once I got into the BPM world, I found the emphasis was on implementing not business processes but what amounted to screen flows. In the BPM world there was pressure to implement flows as quickly as possible and the business’s data needs were not analysed, they were merely documented on a screen-by-screen basis. What’s more, it was not unusual for the same data to appear as fields on multiple screens in several functional areas, often labelled differently. The result was that fields which were logically the same were being implemented multiple times in physical data bases. Outcome: the new systems passed function tests and user acceptance tests but over time became clogged with inconsistent and redundant data that caused technical performance problems as well as business problems.
By the way, there is no “tweaking” a database whose underlying data architecture does not reflect business reality. There is no avoiding a costly refactoring and data migration exercise.
Along with most of my colleagues, the skill of data modelling had withered because we weren’t allowed to use it and so we forgot its importance in describing the very nature of a business. However, over the past ten years, I have come to see data modelling as a basic skill not just for business analysts but also for software developers and testers. As a freelance consultant, I have rarely had the pleasure of working on a greenfields project. I am usually hired for BPM projects where a system is being rebuilt because the first implementation didn’t work, or for projects where the physical data architecture has already been laid down. In every case, there was no data architecture on the business side and the physical data architecture was based on screen requirements alone. Yet none of the highly experienced people on those projects saw that as a problem.
To be clear, I am not criticising those people, after all, until 2009 I had been working along the same lines. I’m criticising what I see as characteristics of BPM projects:
- It’s all about process (with little or no attention to data or decision modelling)
- Build screen flows (instead of realising business processes)
- Get the solution into production as quickly as possible (delivery, instead of adoption by the business users, is
- the measure of success)
- You can always refine the process later (but you can’t refine a flawed physical data architecture)
Over the years, I’ve come to realise that a clear and unambiguous business taxonomy is key to getting the right physical data architecture for a software solution. It is the very foundation upon which a solution is built. I have realised this more with each project and since 2009, I have emphasised data modelling more and more in my analysis of a business. Let me be clear: I am not saying that in my role as a business architect I should be involved in designing the physical architecture. Far from it. However, in my experience, the absence of a clear, unambiguous, technology-agnostic business taxonomy leads to a physical data architecture that does not represent the business reality.
Example:
In the UK, if you wish to make a complaint to a business which is regulated by the Financial Conduct Authority (FCA), there are essentially three stages:
- You make a complaint directly to the business
- If you’re not satisfied with the response, you can take your complaint to the Financial Ombudsman’s Office (FOS)
- If you’re not satisfied with the outcome of that, you can take it to court
Note that businesses only have to report complaints to the FCA if they have not resolved them within a certain time limit.
Even that small amount of information tells you to start modelling a single business entity called “Complaint” and have the following attributes against it:
- Date and time received (for determining the age of the Complaint, e.g., for identifying Complaints to be reported to the FCA)
- Stage
The data held against an instance of the Complaint entity will change or be added to as it passes through the stages above but it remains a single thing. Some years ago I was involved as a Pega Business Architect in the complete rebuilding of a complaints handling BPM system (built using Pega). The previous version (which had gone into production two years earlier but was not deemed fit for purpose – see my blog post “Software delivery does not equal success“) had four different Complaint entities in its physical data architecture:
- A Complaint that has been received but is not yet reportable to the FCA
- A Complaint that is reportable to the FCA
- A Complaint that is being addressed by the FOS
- A Complaint that has gone to court
In the original BPM solution, as the process passed from one stage to the next, an instance of the next type of Complaint was created and the data from the previous type was copied into it, resulting in duplication of data across four Complaint Cases that were actually just a single case. The result of this (and several other problems caused by the data architecture’s not matching the business reality) was that after two years in production, the database became bloated and data was inconsistent and unreliable. Bear in mind that there was no business taxonomy in place for Version 1, the data needs were defined only in screen designs.
The root cause of the problem was that the business described it as four different complaints, instead of a single complaint that could pass through four stages, and the Lead Systems Architect built exactly what was described to him. Unfortunately, the tendency in software development is to assume that what the business says is correct, when in reality most business people do not have the linguistic rigour to clearly and unambiguously define their taxonomy. I have quoted John Ciardi in a previous blog post:
‘The language of experience is not the language of classification.’
Business people have not been trained in such rigour simply because the day-to-day operational needs of their business do not require it but the needs of business architecture and software development do require such rigour. Business analysts (in particular), software developers and testers should be so rigorous but they don’t seem to be. While they are not, businesses will continue to spend millions on rebuilds of software which they already spent millions on. A further problem is that staff churn means people move on from one project to another and are not around to learn from their mistakes. What mistakes? They delivered didn’t they? The software went into production, didn’t it? Oh, wait: Software delivery does not equal success.
I’ll write more on business taxonomy and data modelling in my next post.
Kind regards.
Declan Chellar
This post attracted a lot of comments on LinkedIn. Click here to read them.
Know Your Customer (KYC) is primarily about the decisions a financial institution needs to make about a (potential) customer.
However, I have yet to find a definition online that focuses on decisions. Wikipedia’s definition focuses on the process1, while Investopedia2 and The Free Dictionary3 place emphasis on the form that has to be completed. Although the latter makes reference to decision making, it does so almost in passing.
My own definition would be as follows:
“Know Your Customer (KYC) involves the decisions a business makes to ensure due diligence is observed in evaluating risk in relation to both new and existing customers.”
Feel free to challenge my definition, as that would help me improve it.
In my experience, most business analysts are very process-centric but pay little attention to data modelling and none at all to decision modelling. In the case of KYC, the process really only serves to sequence the decisions being made and to provide activities which ensure all the necessary input data are in place before each decision is made.
The fundamental question being asked by KYC is: “Is it safe to do business with this customer?” That question might be formally documented as the name of a decision (model) thus: “Determine Customer Risk Level”. Any other decisions being made prior to asking that are really just leading up to that final question. If it were feasible to gather all the input data up front, then you’d actually only be making that one business decision (which may well consist of a thousand individual business rules) and the process itself would be very short. However, in reality it’s useful to break it up into stages of decision-making to eliminate risky customers earlier without spending too much time gathering data you don’t need.
As you iterate your decision models, the data needs of each statement of logic will either trace back to attributes in the business’s taxonomy, or the taxonomy will have to be updated to reflect the new needs. This assumes, of course, that the business already has a clear and consistent taxonomy in place. Your job is much harder and success is much less likely if it doesn’t.
Many BPM tools, such as Pega4, come with built-in implementations of standard KYC decision logic. Of course, such out-of-the-box solutions need to be customised to suit the needs of each business. Before customisation, however, the Pega Business Architect needs to collaborate with the Pega Systems Architect to do a gap analysis between what the business needs and what the tool can do and before that, you need to model and test what the business needs.
In summary, KYC is primarily about decision making, then about the data needed in order to be able to make those decisions and finally about the process that sequences the decisions and ensures the data is in place each time a decision needs to be made. My recommendation to business analysts working on KYC is that you tackle it with those priorities in mind.
BA techniques needed:
- Decision modelling
- Logical data modelling
- Business process modelling (ideally using BPMN)
Kind regards.
Declan Chellar
I’ve done work for many software delivery organisations and they all have one thing in common: they think delivery of software to the client is success. I beg to differ.
Several years ago, one such organisation delivered a software solution to its client on time and within budget at a cost of roughly £15 million. I imagine backs were clapped all round and champagne corks flew. However, only about 11% of the target user population ever adopted the software, despite the fact that the software met the requirements (which tells me that the requirements were incorrect in the first place, but that’s a topic for another blog post). The rest reverted to manual processes using spreadsheets because they found the new software made their job harder and slower. I won’t go into detail about the causes other than to say that the business provided a handful of “subject matter experts” to represent a user base of thousands and their requirements were taken as gospel by analysts (who acted as little more than stenographers), developers and testers, none of whom could explain so much as the business significance of a field on a screen and none of whom could cite the strategic business goals of the project, nor had read the business case. Incidentally, the 11% who did use the software, mainly did so because they were ordered to by their managers.
About two years after Version 1 of that software went into production, the business decided to address the issues and launched a project to improve it. Version 2 cost a further £10 million and added no new functionality at all, it merely attempted to make version 1 less bad. Version 2 went into production on time and within budget and I imagine that, again, there was much slapping of backs and uncorking of champagne. The adoption of Version 2 went up to 18% of the target user population, despite the fact that the software met the requirements. The same issues I mentioned above had repeated themselves. Nobody had learned anything and the same mistakes were made because everyone within the delivery organisation still thought of Version 1 as a successful delivery.
Several years after kicking off the development of Version 1, and £25 million later, 88% of users were still doing their work in MS Excel!
Delivery is not success. Adoption is success. Realisation of strategic business objectives is success. The sooner delivery organisations learn this and operate accordingly, the better.
Kind regards.
Declan Chellar
Related posts:
|
|
