An introduction to the meaning of Events in BPMN.
This video is a short introduction to the meaning of the shapes but is not an exhaustive tutorial on how to use them.
|
An introduction to the meaning of Events in BPMN. This video is a short introduction to the meaning of the shapes but is not an exhaustive tutorial on how to use them. An introduction to the meaning of Pools and Lanes in BPMN. This video is a short introduction to the meaning of the shapes but is not an exhaustive tutorial on how to use them. Rather than jumping straight into modelling process steps, set out the scope of the process first. Here is a method you can use to do that. Before we get into the vocabulary and grammar of BPMN 2.0, let’s have a quick look at what it is and why I think you should be using it for process modelling. If you find this tutorial useful, please subscribe to my YouTube channel for more. Thank you. As a business process modeler, you might find yourself modelling what you think is one process, only to find that it is several processes. This can dramatically alter your estimate of how much effort is required. I learned this to my cost many years ago. This video outlines my approach to defining the scope of a business process, so you can better estimate how many processes need to be modelled, mitigate the risk of your work expanding unexpectedly, keep yourself focused on what is relevant and provide clarity to all stakeholders from the outset. This tutorial is aimed at people who are new to process modelling and experienced process modelers who want to take a more structured approach. If you find this tutorial useful, please subscribe to my YouTube channel for more. Thank you. In Part 2, we compared how a Case life cycle might look in Pega’s Case Life Cycle Designer versus BPMN. Here, in Part 3, we’ll consider when you should and should not use Pega’s Case Life Cycle Design tool to model the business process. As we have seen, if you are working on understanding the business process, a model in BPMN gives you a much more ‘joined-up’ view. Ideally, by the time you get into the high level design of your Pega solution, the business will have already worked with appropriately experienced business analysts to produce models of their “To Be” business process in BPMN and those models will be the input to your Pega design. In fact, they should be an input to the Inception phase. Despite the fact that BPMN has been an international standard for modelling business processes for more than a decade, my experience is that most BAs don’t yet know how to use it and so it’s unlikely that a business will provide robust process models as inputs to the Inception phase of your project. However, even if the business does provide robust process models, a corresponding Pega Case Life Cycle Model (CLCM) is still not necessarily advisable. When should you consider not producing a CLCM? You need to model an entire business process and not just the tasks that are to be implemented in Pega. The business entity represented by a Pega Case can be acted on by more than one business process. The business process does not require any human intervention. If your business process cannot be represented by a CLCM, it doesn’t mean it cannot be implemented in Pega. Far from it, Pega is a very good tool for implementing automated business processes. Your job as a BA is to articulate the business need clearly, unambiguously and concisely. If you do that with tools and techniques other than Pega’s CLCM, rest assured that the Pega LSA will design a good technical solution. However, if your only background in doing analysis for a Pega project is the Pega BA training course, you are likely to force your business process(es) into the CLCM when it is not appropriate, you will imply things that will confuse and misdirect the LSA, leading to delays and a dissatisfied customer. Remember that the Pega BA training course is an “essentials” course, not an exhaustive one. Regardess of whether a CLCM is appropriate, if the business does not bring robust process models to the table, my recommendation is that you take some time to work with the business to produce them. I would first establish the scope of the target process or processes. See the link at the end of this post for a tutorial on how to do that. In the case of a straightforward process such as the ‘Manage Expense Claim’ process we saw in Part 2, I hope you can see that it would only take a few minutes to produce the high-level view of the process in BPMN; there wouldn’t be a significant delay in producing the CLCM in Pega and you would have more confidence that the model in Pega represented the real business need. In fact, one person on the team could model the life-cycle in Pega while the BA models it in BPMN, so there would be no delay at all. This is akin to what Pega calls a “Real-time Whiteboard” session. Indeed, one of Pega’s criteria for deciding whether to run such a session is that the scope is less complex. However, if you didn’t get an accurate view of the complexity of the scope in the first place, you may mistakenly decide to use a “Real-time Whiteboard” or even “Real-time Capture” session and then find you are trying to build a prototype for a process that you don’t understand. If the business area is much more sophisticated, such as the processes to handle a tax fraud case, there is all the more reason to model the processes in BPMN because you don’t want to get too far into your technical solution design before discovering that you haven’t understood the business process (or that the business people didn’t explain the process well). Other advantages of modelling processes in BPMN before (or, less ideally, at the same time as you model the life cycle in Pega):
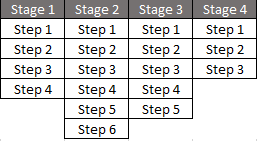
If you do decide to produce a model using BPMN (or the customer provides one), don’t forget to attach each version of the model to the Specification in Pega that corresponds to your Case Type. Kind regards. Declan Chellar Related posts: A lot of people think the complexity of a process is about the number of stages and steps it has but it’s not. I have often seen BAs do an initial analysis of a business process by producing a diagram like this:
This is fine, as long as you have already established the scope of the process (click here for my tutorial on that on YouTube) and you are planning to elaborate the process beyond this simplistic diagram. Unfortunately, I have been on projects where the BA thought that was enough. A poor way to understand the complexity is simply to count up the number of stages and steps. However, a process is more than a count of its steps. The real complexity from a software implementation point of view lies primarily in the following:
Any other steps are going to be about gathering data either to make decisions during the process you are modelling, to send data to other processes or display data to the user. I won’t go into interfaces because they are for the technical solutions architect to explore (although the BA may be involved in identifying those interface points). In any case, if your process model is technology-agnostic, then interfaces will not be relevant yet. The significance of decision points is often overlooked, however, largely due to a lack of awareness of the power of decision modelling. Most BAs I’ve met still think in terms of business rules, instead of decision logic. Moreover, they often start thinking about business rules too late. As soon as you have defined the scope of the business process, you should ask the business what key decisions need to be made within each process stage. At this point, the order of them is not important. It’s unlikely the business will be able to remember every step that needs to be performed in the process but it is quite likely they will remember the important decisions that need to be made. You need to understand two things about a business decision at this stage in your analysis:
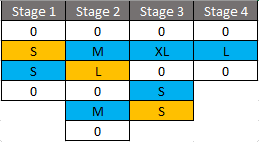
This information is enough to be able to ‘t-shirt size’ those decisions. I don’t have a formula for calculating the complexity of a business decision based on those two pieces of information but I’m sure you can see that a decision that can produce two possible outputs based on three inputs will be a lot simpler to analyse, model, test and implement that one that can produce five possible outputs based on 300 separate input data. The technical solutions architect will size any interface points and you can produce something like this:
In this example, the zeroes represent steps that just gather or present data, while the ambers and blues represent decision points and interface points. When asking the business to identify the decisions they have to make, help them identify hidden decisions, i.e., ones that they are so used to making that they don’t give them much thought. Examples could be: duplicate checks, whether to send an email, how to determine what data to put in that email, data validation logic, etc. In a loan application process, don’t assume that the only decision being made is whether to approve the loan. Taking a decision-focused view of the business process will help you understand the true sophistication of the process. As for multi-instance alignment, such as the example of the process for filling a vacancy versus the process for managing and application for that vacancy, you have to identify each process and estimate its complexity separately. Kind regards. Declan Chellar Related posts: In Part 1, we went through some of the key terms Pega terms in Case Life Cycle modelling. Here, in Part 2, we’ll compare modelling a Case life cycle using Pega 7’s modelling tool with BPMN 2.0. The life cycle view of a Case in Pega 7 is similar to the Discovery Map in Pega 6.
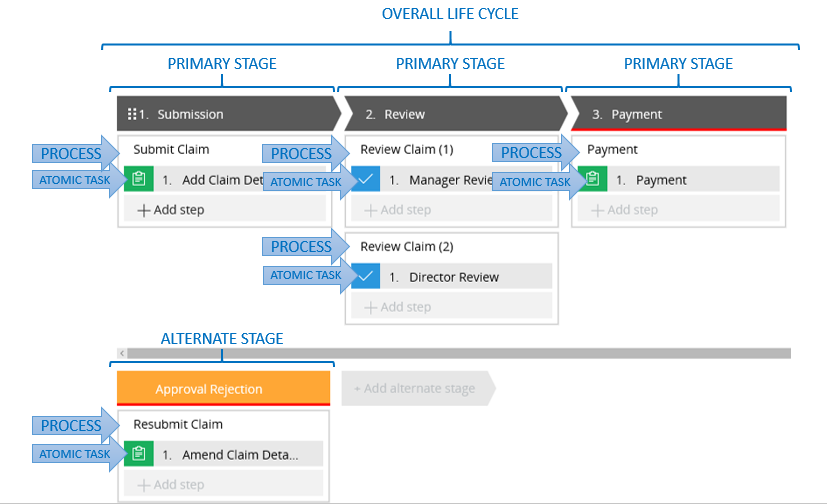
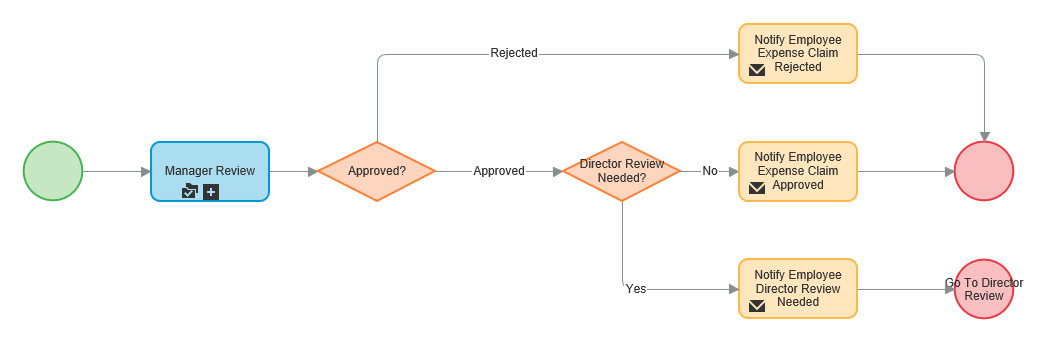
However, other than the sequence of the three primary stages, it is not possible to show the flow of the life cycle in Pega 7. If you are using it as a high-level technical solution design tool, that’s fine, but it conceals too much of the process flow to be useful in gaining (and displaying) an initial understanding of the business process. As an analysis tool, it has the same weaknesses as its predecessor, the Discovery Map. In this model, it’s not explicit that ‘Review Claim (2)’ is actually an alternate path. Moreover, while you can see that ‘Approval Rejection’ is an alternate stage, you cannot see where it branches from the primary. Using BPMN, however, you can see at a glance the high-level view of the entire life cycle, what the key stages are, what the primary path is (which I have marked in blue below), what roles are involved, what the alternate activities are (in grey) and what the business exceptions are (in pink) and then drill down into the sub-process according to your audience.
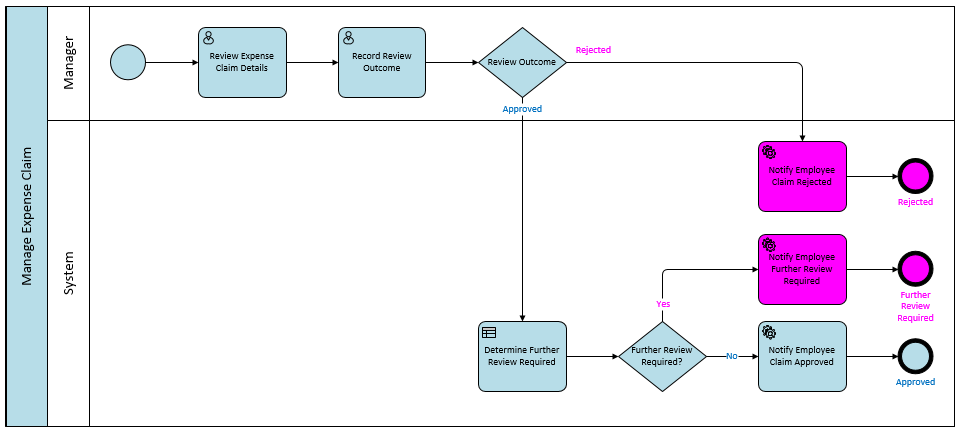
Even with this high-level overview of the business process, you can start to build test scenarios to make sure the process works at a business level before implementing anything in Pega. I’m a big fan of testing the business logic before you implement, so that when you test the software, you are testing only that the software works and not that the business logic makes sense. Notice that I have re-used the sub-process “Review Expense claim”. Any differences can be handled by alternate paths in the child diagram or in the logic of any decision points in the child diagram. In the Case Life Cycle Model, such re-use is not obvious, nor even suggested. The fact that “Review Claim (1)” and “Review Claim (2)” are labelled differently means they are different processes in Pega. In Pega 7, you can model the flow of a particular path through a particular Stage (remember, this is what Pega calls a ‘process’). Take the ‘Review Claim (1)’ process from the Pega life cycle model above, for example:
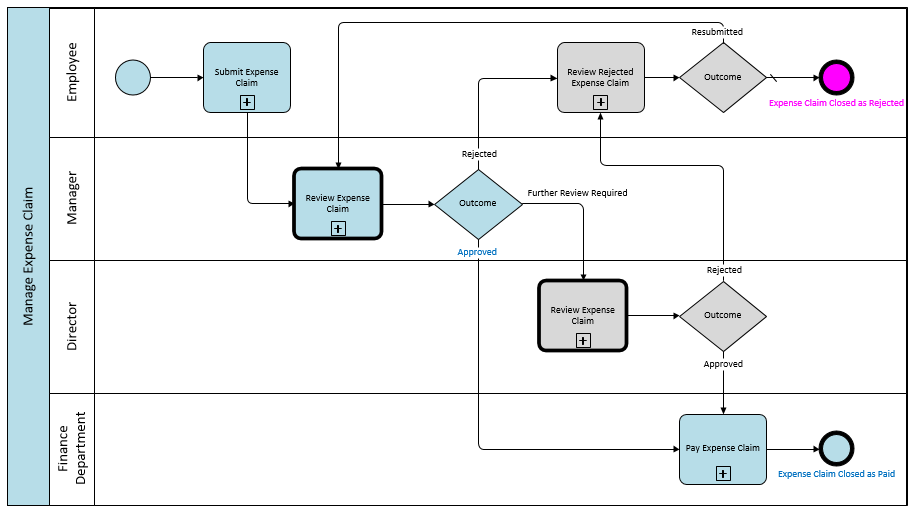
Here is the corresponding diagram for the ‘Review Expense Claim’ sub-process in BPMN:
I’m sure you can see that if you gave that diagram to Pega developers instead of a textual use case, they would find it much easier to understand what flow to build. This sub-process diagram covers both Pega processes “Review Claim (1)” and “Review Claim (2)”. How? By handling the difference inside the decision logic for the task “Determine Further Review Required”. In essence, one of the factors taken into account by the logic is the user’s business role; if it is “Director”, then a further review is not required. Note: in Pega flows, the diamond shape represents a Decision Rule that holds the implementation of the decision logic. In BPMN, the diamond shape (called a ‘gateway’) simply interrogates the outcome of the decision logic, while a model of the logic itself sits in a Decision Model behind the corresponding ‘business rule’ task (in this case, ‘Determine Further Review Required’). Here’s an important point for traceability: I would add a Specification in Pega of type User Story to represent any atomic tasks in the BPMN model. In the case of ‘Determine Further Review Required’ the actual business logic I would model and test in a Decision Model of the same name. The logic (business rules) in the Decision Model would essentially be the requirements. Neither a Process Model nor a Pega Specification is an appropriate mechanism for modelling business logic. Any Decision Rules in Pega could be traced back to the Decision Model via the relevant Specification and the ‘Determine Further Review Required’ activity in the Process Model. I hope you have found this post useful. Thanks for taking the time to read it. For bonus points, have another look at the second BPMN diagram above (click here if you don’t want to scroll back up) and tell me:
In Part 3, we’ll consider when you should and should not use Pega’s Case Life Cycle Design tool to model the business process. Kind regards. Declan Chellar Related posts: Some years ago, I was asked: ‘What is the difference between a Business Analyst and a Business Architect?’ My reply was that a Business Architect was someone who can apply the techniques of business analysis to an architectural framework in a technology-agnostic way. There are other differences but that was what occurred to me at the time. However, that led me to ask myself: ‘What is a Business Architect?’ I think there are two types, broadly speaking. One would be someone who can truly shape a business and decide, or at least advise, what its business model should be, what strategies it should put in place and what it needs to do to implement those strategies. I am not that type of business architect. That kind of strategic advisory role requires deep knowledge and insight into a particular business and a particular industry. However, the people with that knowledge often lack the formal language/framework to model their ideas. As the poet John Ciardi said: “The language of experience is not the language of classification” (which is why, on software development projects, simply writing requirements in business language so often leads to business people saying during UAT: “Yeah, but that’s not what we meant”). My area of expertise is the language of classification, or, rather, languages because each modelling technique is a language of sorts with its own vocabulary, grammar and syntax. Modelling techniques also allow variations in method and style, which are effectively dialects. In other words, I am a technician, not a strategist. I am a ghost writer. I cannot tell you what your strategic goals should be but I can help you put structure on them to make them clear and unambiguous. I cannot tell you what your business model should be but I can help you describe it formally in the language of the Business Model Canvas. In asking you the kind of questions the rigour of the canvas demands, I can help you articulate things that are so normal to you that you wouldn’t otherwise have thought they needed to be articulated, or help you think of things you wouldn’t otherwise have thought of at all. Business Architecture is typically defined as:
With that in mind, I would say the strategist provides the content of that blueprint, while the technician provides the form. Ideally, an organisation would have a Business Architect who is a combination of strategist and technician but a strategist would likely not have the time to gain experience in the detail of technical models of the 2nd row of the Zachman Framework. On the other hand, a technician would not likely have the time to gain the business experience. However, their experience and skill sets are complementary. In fact, my view is that the 1st row of the Zachman Framework is where the two types of Business Architect mostly collaborate. If I were to be precise, and those who have worked with me know that is one of my strengths, I would label myself a “Business Architecture Analyst” in that I analyse the architecture of a business, rather than the business itself. Well, I’m glad I cleared that up. What are your thoughts? Kind regards. Declan Chellar |